Блок "Автоподбор факторов. Регрессия"
Блок доступен начиная с версии 1.0
Назначение блока
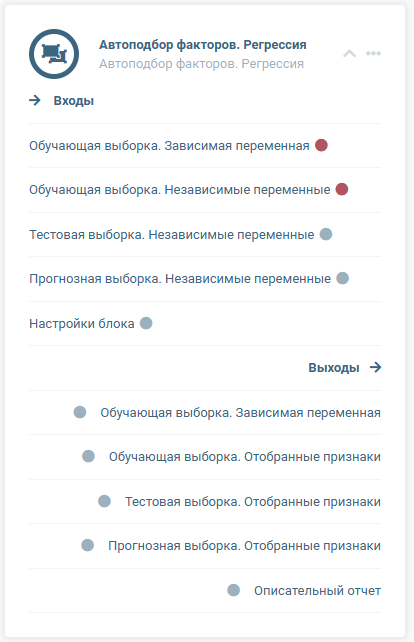
Блок предназначен для автоматического отбора наиболее значимых признаков для решения задачи регрессии.
Чтобы начать работать с блоком, его необходимо выбрать в библиотеке и переместить в область графа.
Настройки блока
Работа с настройками блока осуществляется через его локальное меню (пункт Настройки):
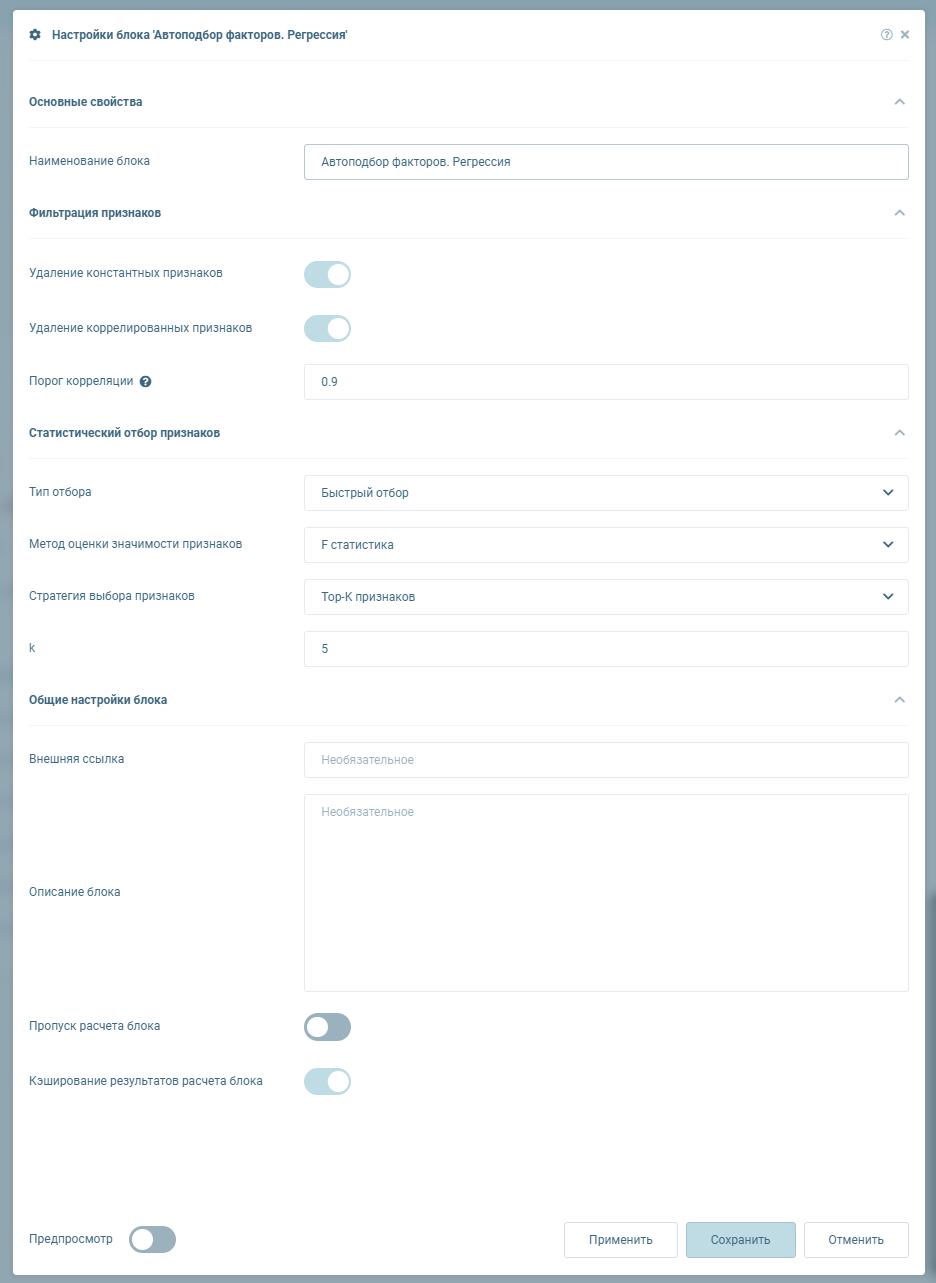
Модальное окно настроек представлено ниже:
Общие настройки блоков описаны в отдельном разделе.
Раздел "Фильтрация признаков"
| Наименование | id настройки | Тип | Обязательное | Описание |
|---|---|---|---|---|
| Удаление константных признаков | del_const | Флаг | Нет | По умолчанию True |
| Удаление коррелированных признаков | del_corr | Флаг | Нет | По умолчанию True |
| Порог корреляции | corr | Целое число | Нет | По умолчанию 0.9. Настройка доступна, если флаг "Удаление коррелированных признаков" равен True |
Раздел "Статистический отбор признаков"
| Наименование | id настройки | Тип | Обязательное | Описание |
|---|---|---|---|---|
| Тип отбора | type_select | Выпадающий список | Да | По умолчанию "Быстрый отбор". Поле поддерживает единичную отметку. Содержит следующие элементы: - Быстрый отбор ("fast"); - Метод RFECV ("rfecv") |
В зависимости от выбранного типа отбора задаётся разный набор параметров. Параметры распределены в отдельные таблицы.
Настройки при типе отбора "Быстрый отбор"
| Наименование | id настройки | Тип | Обязательное | Описание |
|---|---|---|---|---|
| Метод оценки значимости признаков | score_func | Выпадающий список | Нет | По умолчанию "F статистика". Поле поддерживает единичную отметку. Содержит следующие элементы: - F статистика ("f_regression"); - Коэффициент Пирсона ("r_regression"); - Взаимная информация ("mutual_info_regression") |
| Стратегия выбора признаков | strat_select | Выпадающий список | Нет | По умолчанию "Top-K признаков". Поле поддерживает единичную отметку. Содержит следующие элементы: - Top-K признаков ("select_k_best") - Топ % ("select_percentile") |
| k | k | Целое число | Нет | По умолчанию 5. Значение должно принадлежать промежутку [0; Количество факторов обучающей выборки]. Настройка доступна, если в выпадающем списке "Стратегия выбора признаков" выбран элемент "Top-K признаков" |
| % | percent | Вещественное число | Нет | По умолчанию 0.5. Значение должно принадлежать промежутку (0,1]. Настройка доступна, если в выпадающем списке "Стратегия выбора признаков" выбран элемент "Топ %" |
Настройки при типе отбора "Метод RFECV"
| Наименование | id настройки | Тип | Обязательное | Описание |
|---|---|---|---|---|
| Тип кросс-валидации | cv_type | Выпадающий список | Нет | По умолчанию "Временной ряд". Поле поддерживает единичную отметку. Содержит следующие элементы: - K-Фолд ("KFold"); - Временной ряд ("TimeSeriesSplit") |
| Количество фолдов | cv_splits | Целое число | Нет | По умолчанию 3. Значение должно быть больше или равно 0 |
| Метрика | scoring | Целое число | Нет | По умолчанию "Средняя квадратичная ошибка MSE". Поле поддерживает единичную отметку. Содержит следующие элементы: - Коэффициент детерминации R2 ("r2") - Средняя абсолютная ошибка MAE ("mean_absolute_error") - Средняя квадратичная ошибка MSE ("mean_squared_error") - Корень из средней квадратичной ошибки RMSE ("root_mean_squared_error") - Средняя абсолютная процентная ошибка MAPE ("mean_absolute_percentage_error") |
| Минимум признаков для отбора | min_features_to_select | Целое число | Нет | По умолчанию 1. Значение должно принадлежать промежутку [0; Количество факторов обучающей выборки] |
| Начальное положение системы | random_state | Целое число | Нет | По умолчанию 123. Значение должно быть больше или равно 0 |
Входы блока
| Наименование выхода | Тип | Описание |
|---|---|---|
| Обучающая выборка. Зависимая переменная | DataFrame | DataFrame с одним рядом |
| Обучающая выборка. Независимые переменные | DataFrame | DataFrame с набором признаков |
| Тестовая выборка. Независимые переменные | DataFrame | DataFrame с набором признаков |
| Прогнозная выборка. Независимые переменные | DataFrame | DataFrame с набором признаков |
| Настройки блока | JSON | См. описание ниже |
Вход "Настройки блока"
Если настройки передаются на вход блока, его внутренние настройки игнорируются. Для корректной передачи настроек необходимо:
-
Передать их в формате JSON.
-
Обязательно указать тип отбора, который требуется выполнить, используя параметр "type_select" (например, "type_select": "rfecv"). Это обязательный параметр. Если тип отбора не указан, расчет произведен не будет.
-
Указать все необходимые параметры выбранной модели по принципу "id_настройки": значение. Идентификаторы настроек и перечислений приведены в таблицах выше. Если параметр указан неверно или отсутствует, будет использовано значение по умолчанию.
Выходы блока
| Наименование выхода | Тип | Описание |
|---|---|---|
| Обучающая выборка. Зависимая переменная | DataFrame | |
| Обучающая выборка. Отобранные признаки | DataFrame | |
| Тестовая выборка. Отобранные признаки | DataFrame | |
| Прогнозная выборка. Отобранные признаки | DataFrame | |
| Список выбранных признаков | Список | |
| Описательный отчет | html | Статистический отчет о работе метода |
События блока
В блоке нет событий.
Описание работы блока
Блок предназначен для исключения нерелевантных или избыточных признаков, улучшения качества моделей машинного обучения и сокращения времени обучения за счет снижения размерности входных данных.
Результаты работы блока:
- Набор отобранных рядов.
- HTML-отчет о работе блока.
Настройки блока можно задать через графический интерфейс или передать их на соответствующий вход.
Блок «Автоподбор факторов» работает в два этапа:
- Фильтрация данных: удаление константных рядов (признаков с постоянными значениями); удаление рядов, чья корреляция с зависимой переменной превышает заданный порог.
- Основной отбор. Применяется только к оставшимся после фильтрации рядам. Доступны два режима:
- Быстрый отбор;
- Валидационный метод RFECV (Recursive Feature Elimination with Cross-Validation) на основе регрессии Lasso.
Ограничения блока
- Метод работает только с объектами pandas.DataFrame
- Обучающая выборка не должна содержать полностью пустых столбцов.
- Тестовая и прогнозная выборки должны иметь тот же набор признаков, что и обучающая выборка.
- Зависимая переменная должна состоять только из одного столбца.
- Зависимая и независимые переменные должны иметь одинаковое количество наблюдений.
- Все входные данные должны быть числовыми и не содержать пропусков и бесконечных значений.
- Индексы строк зависимой и независимых переменных обучающей выборки должны совпадать.